This post will talk about building linear and non-linear models of trip rates in R. Â If you haven’t read the first part of this series, please do so, partly because this builds on it.
Simple Linear Models
Simple linear models are, well, simple in R. Â An example of a fairly easy linear model with two factors is:
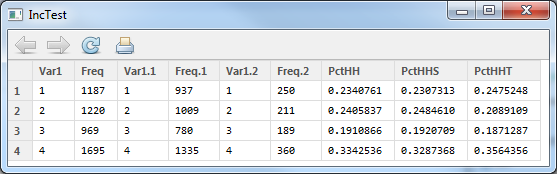
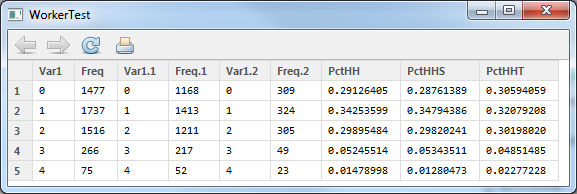
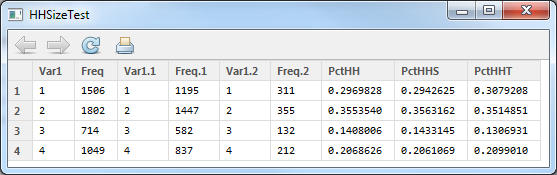
inTab.hbsh
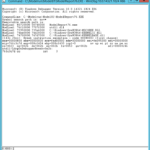
This creates a simple linear home-based-shopping trip generation model based on workers and household size. Â Once the estimation completes (it should take less than a second), the summary should show the following data:
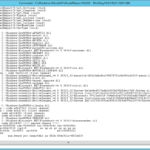
> summary(hbsh.lm.W_H)
Call:
lm(formula = N ~ Workers4 + HHSize6, data = hbsh)
Residuals:
Min 1Q Median 3Q Max
-2.2434 -1.1896 -0.2749 0.7251 11.2946
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.79064 0.10409 17.203 < 2e-16 ***
Workers4 -0.02690 0.05848 -0.460 0.646
HHSize6 0.24213 0.04365 5.547 3.58e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.649 on 1196 degrees of freedom
Multiple R-squared: 0.03228, Adjusted R-squared: 0.03066
F-statistic: 19.95 on 2 and 1196 DF, p-value: 3.008e-09
What all this means is:
Trips = -0.0269*workers+0.24213*HHSize+1.79064
The important things to note on this is that the intercept is very significant (that's bad) and the R2 is 0.03066 (that's horrible). Â There's more here, but it's more details.
Non-Linear Least Squares
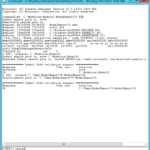
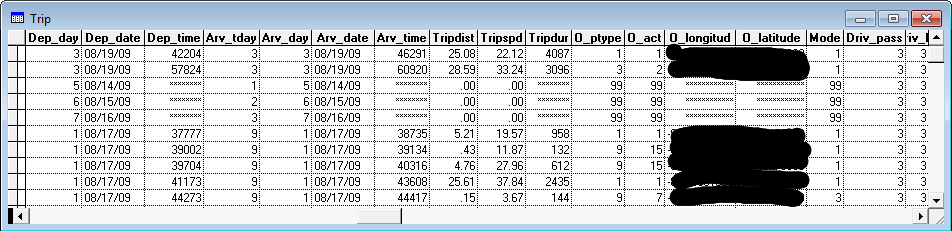
When doing a non-linear model, the nls function is the way to go. Â The two lines below create a trips data frame, and then run a non-linear least-squares model estimation on it (note that the first line is long and wraps to the second line).
trips=3),
start=c(a=1,b=1),trace=true)
The second line does the actual non-linear least-squares estimation. Â The input formula is T=a*e^(HHSize+b). Â In this type of model, starting values for a and b have to be given to the model.
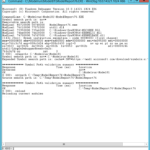
The summary of this model is a little different:
> summary( trips.hbo.nls.at3p)
Formula: T.HBO ~ a * log(HHSize6 + b)
Parameters:
Estimate Std. Error t value Pr(>|t|)
a 1.8672 0.1692 11.034 < 2e-16 ***
b 1.2366 0.2905 4.257 2.58e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.095 on 402 degrees of freedom
Number of iterations to convergence: 4
Achieved convergence tolerance: 1.476e-07
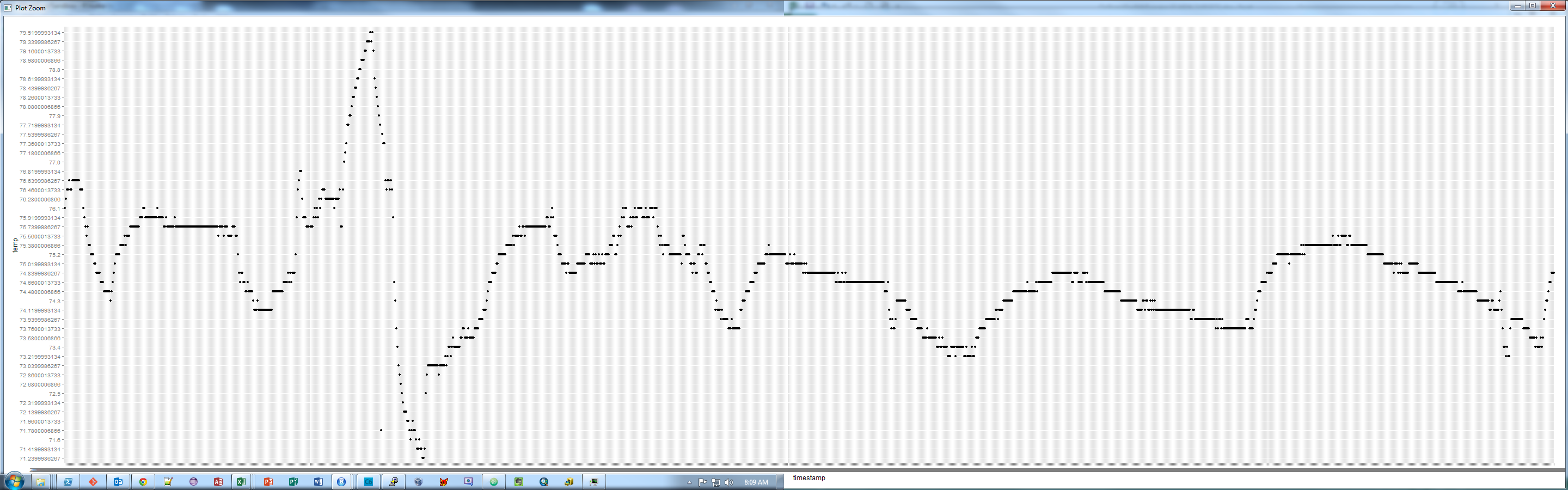
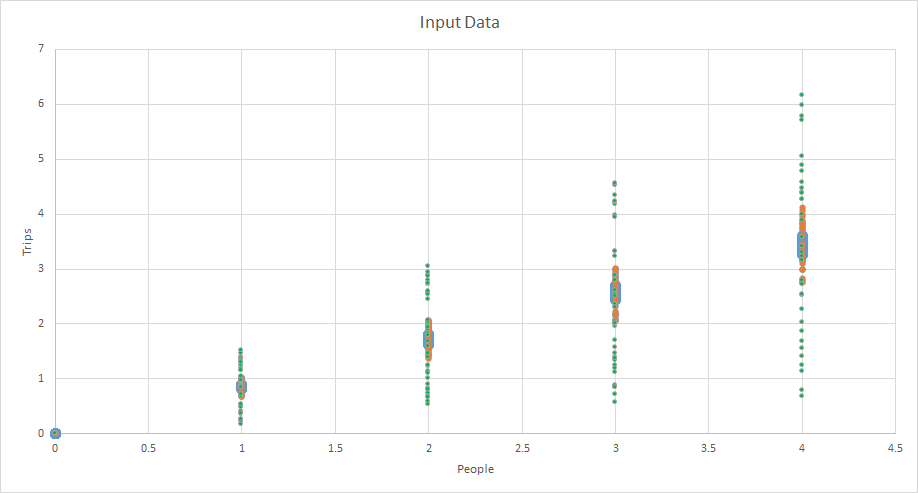
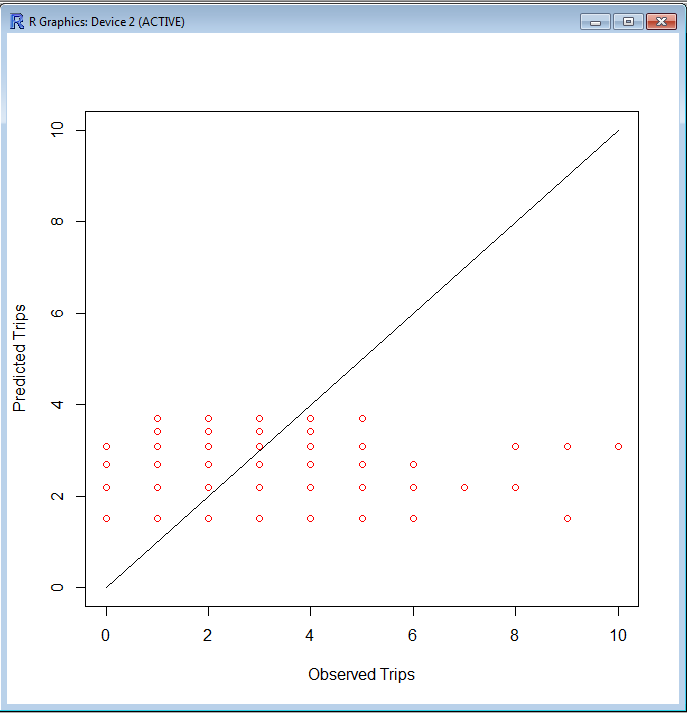
It doesn't perform R2 on this because it can't directly. However, we can because we know the actual values and the model predicts the values. So, one thing that can be done is a plot:
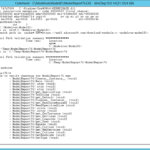
> plot(c(0,10),c(0,10),type='l',xlab='Observed Trips',ylab='Predicted Trips')
> points(subset(trips,AreaType>=3)$T.HBO,fitted(trips.hbo.nls.at3p),col='red')
The resulting graph looks like this. Not particularly good, but there is also no scale as to the frequency along the 45° line.
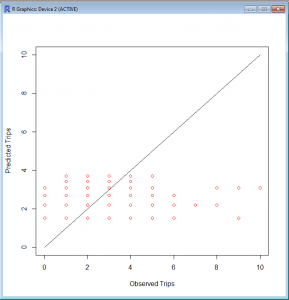
R2 is still a good measure here. There's probably an easier way to do this, but this way is pretty simple.
testTable=3)$T.HBO,fitted(trips.hbo.nls.at3p)))
cor(testTable$X1,testTable$X2)
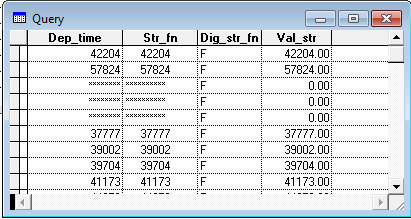
Since I didn't correct the column names when I created the data frame, R used X1 and X2, as evidenced by checking the summary of testTable:
> summary(testTable)
X1 X2
Min. : 0.000 Min. :1.503
1st Qu.: 1.000 1st Qu.:1.503
Median : 2.000 Median :2.193
Mean : 2.072 Mean :2.070
3rd Qu.: 3.000 3rd Qu.:2.193
Max. :23.000 Max. :3.696
So the R2 value is pretty bad...
> cor(testTable$X1,testTable$X2)
[1] 0.2755101
It's better than some of the others, after all, this is semirandom human behavior.
That's it for now. My next post will be... MORE R!
Also, I have a quick shout-out to Jeremy Raw at FHWA for help via email related to this. He helped me through some issues via email, and parts of his email helped parts of this post.























































")

")







