Iterating Through DBFs – R Style!
Anyone familiar with transportation modeling is familiar with processes that iterate through data. Â Gravity models iterate, feedback loops iterate, assignment processes iterate (well, normally), model estimation processes iterate, gravity model calibration steps, shadow cost loops iterate… the list goes on.
Sometimes it’s good to see what is going on during those iterations, especially with calibration. Â For example, in calibrating friction factors in a gravity model, I’ve frequently run around 10 iterations. Â However, as an experiment I set the iterations on a step to 100 and looked at the result:
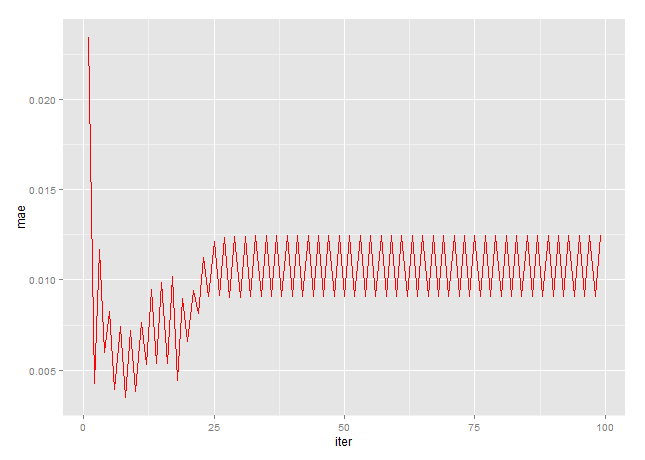
This is the mean absolute error in percentage of observed trips to modeled trips in distribution. Â Note the oscillation that starts around iteration 25 – this was not useful nor detected. Â Note also that the best point was very early in the iteration process – at iteration 8.
After telling these files to save after each iteration (an easy process), I faced the issue of trying to quickly read 99 files and get some summary statistics. Â Writing that in R was not only the path of least resistance, it was so fast to run that it was probably the fastest solution. Â The code I used is below, with comments:
Tags: R, reporting, statistics



